如何使用numpy,使得其在计算时更快?
1. 更快的 numpy
1.1. mkl 加速
Numpy 的许多函数不仅是用C实现了,还使用了BLAS(Basic Linear Algebra Subprograms,基础线性代数程序集)(一般Windows下link到MKL的,Linux下link到OpenBLAS)。基本上那些BLAS实现在每种操作上都进行了高度优化,例如使用AVX向量指令集,甚至能比你自己用C实现快上许多,更不要说和用Python实现的比
英特尔数学核心库(Intel MKL) 的开发是致力于加速在intel处理器上进行的数学运算。该库支持 Windows、Linux和 macOS 操作系统。
在安装 NumPy 的时候,为了速度更快,我们可以安装带 mkl 的版本。
安装
可以通过以下方式安装:
1. conda,
2. 下载二进制whl文件,(Unofficial Windows Binaries for Python Extension Packages, 地址)
pip install intel-numpy conda install numpy # conda 版本已经是优化过的 Anoconda (base)环境里面已经安装过
查看
import numpy as np np.show_config() >>> # No MKL blas_mkl_info: NOT AVAILABLE blis_info: NOT AVAILABLE openblas_info: library_dirs = ['C:\\projects\\numpy-wheels\\numpy\\build\\openblas'] libraries = ['openblas'] language = f77 define_macros = [('HAVE_CBLAS', None)] blas_opt_info: library_dirs = ['C:\\projects\\numpy-wheels\\numpy\\build\\openblas'] libraries = ['openblas'] language = f77 define_macros = [('HAVE_CBLAS', None)] lapack_mkl_info: NOT AVAILABLE openblas_lapack_info: library_dirs = ['C:\\projects\\numpy-wheels\\numpy\\build\\openblas'] libraries = ['openblas'] language = f77 define_macros = [('HAVE_CBLAS', None)] lapack_opt_info: library_dirs = ['C:\\projects\\numpy-wheels\\numpy\\build\\openblas'] libraries = ['openblas'] language = f77 define_macros = [('HAVE_CBLAS', None)] # with mkl mkl_info: libraries = ['mkl_rt'] library_dirs = ['D:/ProgramData/Anaconda3\\Library\\lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\include', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\lib', 'D:/ProgramData/Anaconda3\\Library\\include'] blas_mkl_info: libraries = ['mkl_rt'] library_dirs = ['D:/ProgramData/Anaconda3\\Library\\lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\include', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\lib', 'D:/ProgramData/Anaconda3\\Library\\include'] blas_opt_info: libraries = ['mkl_rt'] library_dirs = ['D:/ProgramData/Anaconda3\\Library\\lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\include', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\lib', 'D:/ProgramData/Anaconda3\\Library\\include'] libraries = ['mkl_rt'] library_dirs = ['D:/ProgramData/Anaconda3\\Library\\lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\include', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\lib', 'D:/ProgramData/Anaconda3\\Library\\include'] lapack_opt_info: libraries = ['mkl_rt'] library_dirs = ['D:/ProgramData/Anaconda3\\Library\\lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\include', 'C:\\Program Files (x86)\\IntelSWTools\\compilers_and_libraries_2019.0.117\\windows\\mkl\\lib', 'D:/ProgramData/Anaconda3\\Library\\include']
1.2. 多维数据在内存的形式
在 Numpy 中, 创建 2D Array 的默认方式是 C-type 以 row 为主在内存中排列, 而如果是 Fortran 的方式创建的, 就是以 column 为主在内存中排列。
col_major = np.zeros((10,10), order='C') # C-type row_major = np.zeros((10,10), order='F') # Fortran
1.3. 数组选择copy Vs view
在 Numpy 中, 有两个很重要的概念, copy 和 view. copy 顾名思义, 会将数据 copy 出来存放在内存中另一个地方, 而 view 则是不 copy 数据, 直接取源数据的索引部分.
选择数据的时候, 我们常会用到 view 或者 copy 的形式. 我们知道了, 如果能用到 view 的, 我们就尽量用 view, 避免 copy 数据. 那什么时候会是 view 呢? 下面举例的都是 view 的方式:
------view----- a_view1 = a[1:2, 3:6] # 切片 slice a_view2 = a[:100] # 同上 a_view3 = a[::2] # 跳步 a_view4 = a.ravel() # 上面提到了 ... # 我只能想到这些, 如果还有请大家在评论里提出 那哪些操作我们又会变成 copy 呢? ------copy----- a_copy1 = a[[1,4,6], [2,4,6]] # 用 index 选 a_copy2 = a[[True, True], [False, True]] # 用 mask a_copy3 = a[[1,2], :] # 虽然 1,2 的确连在一起了, 但是他们确实是 copy a_copy4 = a[a[1,:] != 0, :] # fancy indexing a_copy5 = a[np.isnan(a), :] # fancy indexing ... # 我只能想到这些, 如果还有请大家在评论里提出
pandas
--- copy --- df.ix[] df.iloc[] df.loc[] --- view ---
可以发现当选择的列数 大于1 的时候是copy了的,但是如果只选择一列,则没copy,在对其赋值的时候要格外小心。最好还是copy一下吧
有时候我们会经常把一个DataFrame传进一个函数里,又害怕它被函数里面的语句更改了,所以我一般做法是先df.copy()一下,但是其实我们在用ix, iloc, loc 索引的时候就已经进行了拷贝.
1.4. 使用 out 参数
非常有用的 out 参数 --启动view
不深入了解 numpy 的朋友, 应该会直接忽略很多功能中的这个 out 参数 (之前我从来没用过). 不过当我深入了解了以后, 发现他非常有用! 比如下面两个其实在功能上是没差的, 不过运算时间上有差, 我觉得可能是 a=a+1 要先转换成 np.add() 这种形式再运算, 所以前者要用更久一点的时间.
a = a + 1 # 0.035230 a = np.add(a, 1) # 0.032738
如果是上面那样, 我们就会触发之前提到的 copy 原则, 这两个被赋值的 a, 都是原来 a 的一个 copy, 并不是 a 的 view. 但是在功能里面有一个 out 参数, 让我们不必要重新创建一个 a. 所以下面两个是一样的功能, 都不会创建另一个 copy. 不过可能是上面提到的那个原因, 这里的运算时间也有差.
a += 1 # 0.011219 np.add(a, 1, out=a) # 0.008843
带有 out 的 numpy 功能都在这里:Universal functions(https://docs.scipy.org/doc/numpy/reference/ufuncs.html#available-ufuncs). 所以只要是已经存在了一个 placeholder (比如 a), 我们就没有必要去再创建一个, 用 out 方便又有效.
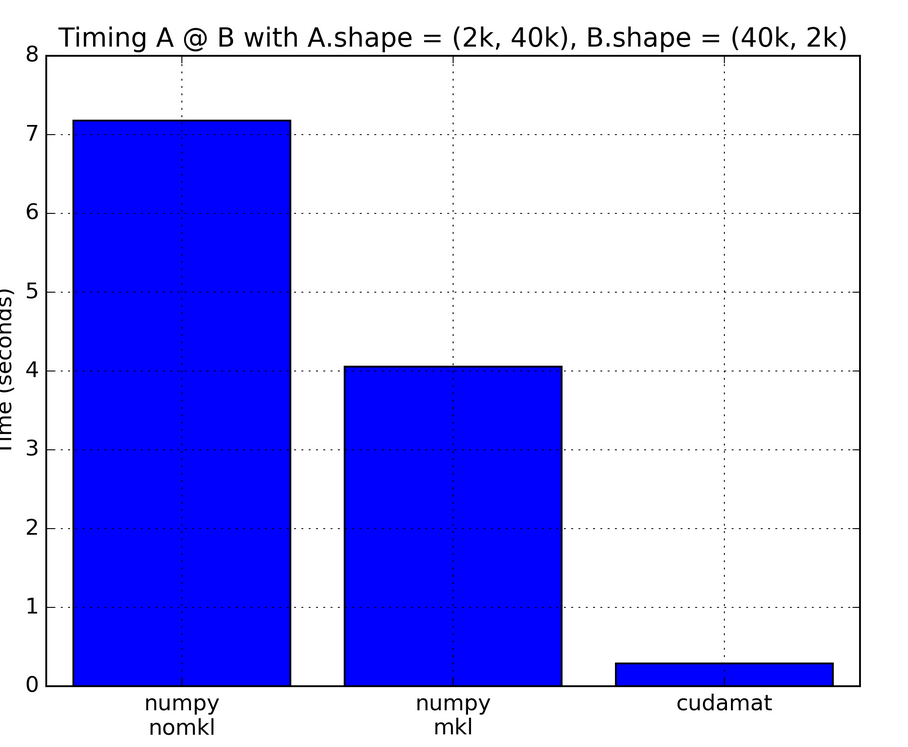
1.5. GPU
numpy 不支持GPU, pytoch 可以作为 GPU 版本的 NumPy 替代品。
用好numpy
在计算方面,实际上有三个概念使NumPy具有强大的功能:
- 向量化
- 广播
- 索引编制
参考: https://realpython.com/numpy-array-programming/
2. 更小的numpy
主要针对内存
<type 'int'> size is 12 <type 'bool'> size is 12 <type 'long'> size is 14 <type 'float'> size is 16 <type 'str'> size is 21 <type 'list'> size is 36 <type 'tuple'> size is 28 <type 'dict'> size is 140 <type 'set'> size is 116 <class 'numpy.float32'> 28 <class 'numpy.float64'> 32 <class 'numpy.int64'> 32 <class 'numpy.int32'> 28 <class 'numpy.int16'> 26 <class 'numpy.ndarray'> 100 # np.int <class 'numpy.ndarray'> 100 # np.float32 <class 'numpy.ndarray'> 104 # np.float64
numpy 默认浮点为float64
3. 测试
# 测试用例1--SVD 奇异值分解 import datetime import numpy as np for i in range (5): t0=datetime.datetime.now() a = np.random.rand(10000, 100) U, s, V = np.linalg.svd(a) t1=datetime.datetime.now() print ("time cost {}".format(t1-t0)) time cost 0:00:12.010129 # ubuntu conda numpy mkl time cost 0:00:13.581722 # ubuntu conda numpy time cost 0:00:12.934425 # windows conda numpy mkl time cost 0:00:13.737275 # windows conda numpy time cost 0:00:20.864863 # colab Linux numpy
连续内存
np.ascontiguousarray
ascontiguousarray函数将一个内存不连续存储的数组转换为内存连续存储的数组,使得运行速度更快。
C order vs Fortran order
C order 指的是行优先的顺序(Row-major Order),即内存中同行的元素存在一起,
Fortran Order则指的是列优先的顺序(Column-major Order),即内存中同列的元素存在一起。
Pascal, C,C++,Python都是行优先存储的,而Fortran,MatLab是列优先存储的。
Contiguous array
contiguous array指的是数组在内存中存放的地址也是连续的(注意内存地址实际是一维的)。
2维数组arr = np.arange(12).reshape(3,4)。数组结构如下
image
在内存里中实际存储如下:
image
arr是 C order 的,在内存是行优先的。如果想要向下移动一列,则需要跳过3个块(例如,从0到4只需要跳过1,2和3)。
如果经过转置,arr.T没有了C连续特性,因为内存中元素的地址不变,同一行中的相邻元素在内存中不是连续的:
image
这时,arr.T变成了Fortran order,因为相邻列中的元素在内存中是相邻存储的。
从性能上来说,获取内存中相邻的地址比不相邻的地址速度要快很多(从RAM读取一个数值的时候可以连着一起读一块地址中的数值,并且可以保存在Cache中),这意味着对连续数组的操作会快很多。
由于arr是C连续的,因此对其进行行操作比进行列操作速度要快。通常来说
np.sum(arr, axis=1) # 按行求和
会比
np.sum(arr, axis=0) # 按列求和
稍微快些。
同理,在arr.T上,列操作比行操作会快些。
使用 np.ascontiguousarray()
Numpy中,随机初始化的数组默认都是C连续的。
经过不规则的slice操作,则会改变连续性,可能会变成既不是C连续,也不是Fortran连续的。
可以通过数组的.flags属性,查看一个数组是C连续还是Fortran连续的
import numpy as np
arr = np.arange(12).reshape(3, 4)
arr.flags
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : False
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
从输出可以看到数组arr是C连续的。
对arr进行按列的slice操作,不改变每行的值,则还是C连续的:arr
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
arr1 = arr[:2, :]
arr1
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7]])
arr1.flags
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : False
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
如果进行在行上的slice,则会改变连续性,成为既不C连续,也不Fortran连续的:arr1 = arr[:, 1:3]
arr1.flags
C_CONTIGUOUS : False
F_CONTIGUOUS : False
OWNDATA : False
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
此时利用ascontiguousarray函数,可以将其变为连续的:arr2 = np.ascontiguousarray(arr1)
arr2.flags
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
参考
从Numpy中的ascontiguousarray说起 - 知乎
Numpy文档
4. 参考资料
-
How To Make Your Pandas Loop 71803 Times Faster https://towardsdatascience.com/how-to-make-your-pandas-loop-71-803-times-faster-805030df4f06 ↩
