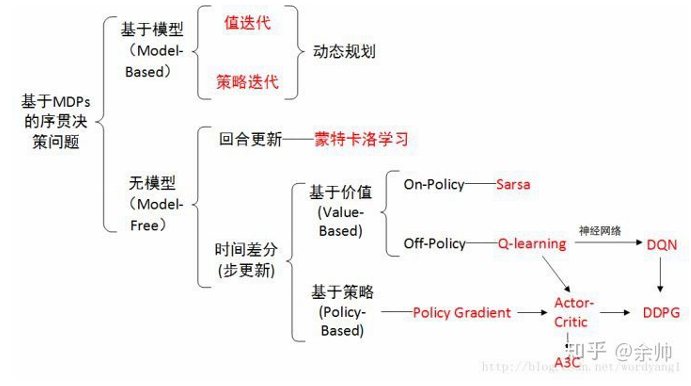
我们有了像 Q-learning 这么伟大的算法, 为什么还要瞎折腾出一个 Actor-Critic? 原来 Actor-Critic 的 Actor 的前生是 Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率.
Actor Critic
一句话概括 Actor Critic 方法:
结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法. Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率.
Actor Critic 方法的优势: 可以进行单步更新, 比传统的 Policy Gradient 要快.
Actor Critic 方法的劣势: 取决于 Critic 的价值判断, 但是 Critic 难收敛, 再加上 Actor 的更新, 就更难收敛. 为了解决收敛问题, Google Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient. 后者融合了 DQN 的优势, 解决了收敛难的问题. 我们之后也会要讲到 Deep Deterministic Policy Gradient. 不过那个是要以 Actor Critic 为基础, 懂了 Actor Critic, 后面那个就好懂了.
下面是基于 Actor Critic 的 Gym Cartpole 实验:
这套算法是在普通的 Policy gradient 算法上面修改的, 如果对 Policy Gradient 算法还不是很了解, 欢迎戳这里. 对这套算法打个比方如下:
Actor 修改行为时就像蒙着眼睛一直向前开车, Critic 就是那个扶方向盘改变 Actor 开车方向的.
Actor Critic (Tensorflow)
或者说详细点, 就是 Actor 在运用 Policy Gradient 的方法进行 Gradient ascent 的时候, 由 Critic 来告诉他, 这次的 Gradient ascent 是不是一次正确的 ascent, 如果这次的得分不好, 那么就不要 ascent 那么多.
DDPG
A3C
参考资料
https://zhuanlan.zhihu.com/p/25498081
[2]. A2C / A3C (Asynchronous Advantage Actor-Critic): Mnih et al, 2016
[3]. PPO (Proximal Policy Optimization): Schulman et al, 2017
[4]. TRPO (Trust Region Policy Optimization): Schulman et al, 2015
[5]. DDPG (Deep Deterministic Policy Gradient): Lillicrap et al, 2015
[6]. TD3 (Twin Delayed DDPG): Fujimoto et al, 2018
[7]. SAC (Soft Actor-Critic): Haarnoja et al, 2018
[8]. DQN (Deep Q-Networks): Mnih et al, 2013
[9]. C51 (Categorical 51-Atom DQN): Bellemare et al, 2017
[10]. QR-DQN (Quantile Regression DQN): Dabney et al, 2017
[11]. HER (Hindsight Experience Replay): Andrychowicz et al, 2017
[12]. World Models: Ha and Schmidhuber, 2018
[13]. I2A (Imagination-Augmented Agents): Weber et al, 2017
[14]. MBMF (Model-Based RL with Model-Free Fine-Tuning): Nagabandi et al, 2017
[15]. MBVE (Model-Based Value Expansion): Feinberg et al, 2018
[16]. AlphaZero: Silver et al, 2017
