1. 系统设计概述
时间不够、资源有限、需要协调。高并发(High Concurrency) 高可用HA
1.1. 性能指标
1.1.1. 响应时间 RT
响应时间 指某个请求从发出到接收到响应消耗的时间。
在对响应时间进行测试时,通常采用重复请求的方式,然后计算平均响应时间。
网络传输时间:N1+N2+N3+N4 应用服务器处理时间:A1+A3 数据库服务器处理时间:A2
$$响应时间=N1+N2+N3+N4+A1+A3+A2$$
1.1.1.1. 思考时间
思考时间:用户每个操作后的暂停时间,或者叫操作之间的间隔时间,此时间内是不对服务器产生压力的。
1.1.2. 吞吐量 Throughput
指系统在单位时间内可以处理的请求数量,通常使用每秒的请求数来衡量。度量并发系统的性能的主要原因。
$$Throughput=\frac{处理请求的数量}{单位时间}=\frac{1}{响应时间 RT}$$
在没有并发存在的系统中,请求被顺序执行,此时响应时间为吞吐量的倒数。例如系统支持的吞吐量为 100 req/s,那么平均响应时间应该为 0.01s。
从业务角度看,吞吐量可以用:请求数/秒、页面数/秒、人数/天或处理业务数/小时等单位来衡量
从网络角度看,吞吐量可以用:字节/秒来衡量
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力
以不同方式表达的吞吐量可以说明不同层次的问题,例如:
以字节数/秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈;
已请求数/秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈。
当没有遇到性能瓶颈的时候,吞吐量与虚拟用户数之间存在一定的联系,可以采用以下公式计算:
$$ Throughput= \frac{处理请求的数量}{单位时间}=\frac{VU*R}{T} $$
其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间
1.1.2.1. QPS 每秒查询率
QPS:Queries Per Second 意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
$$ QPS= 每秒查询次数$$
例如:
请求1次页面,可能产生N次对服务器的请求(页面上有很多html资源,比如图片等),服务器对这些请求次数就可计入QPS之中,QPS=N
1.1.2.2. TPS 事务数/秒
TPS:是Transactions Per Second的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。对1个页面请求一次,形成1个TPS.
$$ TPS= 每秒完成的事务个数$$
例如:
1个事务包括了:
(1)用户请求服务器
(2)服务器自己的内部处理
(3)服务器返回给用户
这三个过程,每秒能够完成1次这三个过程,TPS也就是1;但QPS=3
1.1.2.3. RPS 请求数/秒
RPS 即Requests Per Second的缩写,每秒能处理的请求数目。等效于QPS
$$ RPS(QPS,TPS)= 并发数/平均响应时间 $$
1.1.3. 并发用户数
指系统能同时处理的并发用户请求数量。
并发用户数不是越高越好,因为如果并发用户数太高,系统来不及处理这么多的请求,会使得过多的请求需要等待,那么响应时间就会大大提高。
系统用户数:系统额定的用户数量,如一个OA系统,可能使用该系统的用户总数是5000个,那么这个数量,就是系统用户数。
同时在线用户数:在一定的时间范围内,最大的同时在线用户数量。
虚拟用户数 Vu:
虚拟用户数 Virtual User: 性能测试中通过线程或进程执行脚本来模拟典型用户访问系统行为的用户。
一般情况下,大型系统(业务量大、机器多)做压力测试,5000个用户并发就够了,中小型系统做压力测试,1000个用户并发就足够了
平均并发用户数:
$$C = \frac{nL}{T}$$
C:平均的并发用户数;
n:平均每天访问用户数(login session的数量);
L:一天内用户从登录到退出的平均时间(login session的平均长度);
T:考察的时间段长度(一天内多长时间有用户使用系统);
并发用户数峰值:
$$C^{peak} =C+C^\frac{1}{3}$$
其中:
$C^{peak}$ :并发用户峰值
C: 平均并发用户数.
该公式遵循泊松分布理论。
1.2. 系统性能评价方法
1.2.1. 单个计算机的性能
ulimit -a >>> core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 7823 max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes (-u) 7823 virtual memory (kbytes, -v) unlimited file locks (-x) unlimited ulimit -<command> <command> 含义 -a 显示目前资源限制的设定。 -c <core文件上限> 设定core文件的最大值,单位为区块。 -d <数据节区大小> 程序数据节区的最大值,单位为KB。 -f <文件大小> shell所能建立的最大文件,单位为区块。 -H 设定资源的硬性限制,也就是管理员所设下的限制。 -m <内存大小> 指定可使用内存的上限,单位为KB。 -n <文件数目> 指定同一时间 进程最多可开启的文件数。 -p <缓冲区大小> 指定管道缓冲区的大小,单位512字节。 -s <堆叠大小> 指定堆叠的上限,单位为KB。 -S 设定资源的弹性限制。 -t <CPU时间> 指定CPU使用时间的上限,单位为秒。 -u <程序数目> 用户最多可开启的程序数目。 -v <虚拟内存大小> 指定可使用的虚拟内存上限,单位为KB。
1.2.2. C/S 性能
服务主要影响部分流程|
(客户端)<--------------->[服务端(带宽)<--->(端口)<--->(系统)<--->(内存)<--->(CPU)<--->(磁盘)]
| 项目 | 限制 |
|---|---|
| 带宽 | 服务器带宽就是访问服务器时的最高网络速度,假设最大网速为1MB/s(不是1Mb) ; |
| 端口 | 服务器开放的端口,一般1个服务开放1个端口,对应的客户端连接最多可支持65535个端口,这个是TCP/IP协议定死的了,不可以改变,也就是说一台服务器一个服务下最多支持65535个人同时在线;但是,注意这里是本服务器主动连接 其他服务器的限制是65535,并不是别人连接他的限制3 |
| 系统 | 系统一般会根据硬盘配置对连接数量做简单评估的限制,当然这个也可以手动改,在Linux下查看限制数量可以使用 ulimit -n 命令,这里是65535; |
| 内存 | 除了系统占用一部分内存以外,每个网络连接在使用周期内都需要占用一部分内存,这要看程序的有所不同,假设这里内存为4GB,每个连接占用内存为1KB; |
| CPU | 除了系统任务调度占用的CPU时间外,每个网络连接的数据处理也需要占用一部分CPU时间,这也与程序设计有所不同,假设这里CPU为2核2.5GHz,每个连接占用1MHz; |
| 磁盘 | 磁盘的启动速度的速度较慢,仅有 50 MB/秒,比旋转磁盘(150 MB/秒)、SATA SSD(500 MB/秒)和 PCIe SSD(2000+ MB/秒)要慢 |
综合以上配置得出,该服务器配置并同量,也就是同时支持在线连接数为:
| 项目 | 支持在线连接数量 |
|---|---|
| 带宽 | 1MB/s / 1KB = 1024KB/1KB = 1024 |
| 端口 | 65535 |
| 系统 | 65535 - 1024(假设系统需要使用的部分数量) = 64511 |
| 内存 | (4GB - 500MB(假设系统占用大小)) / 1KB = 3682304KB / 1KB = 3682304 |
| CPU | ((2*2.5GHz)-100MHz(假设系统占用大小))/ 1MHz = 5020MHz / 1MHz = 5020 |
| 磁盘 | 50MB/s / 1kB = 50*1024/1= 51200 |
取以上结果的最小一个就是服务器支持的并发数, 那并发量就是1024;
注意
socket连接=<客户端ip,客户端端口,服务器端ip,服务器端口>
对于确定ip下的某个服务器端口是不能使用超过65536个,但是这不等价于“服务器最多能接受65536个socket连接“
socket连接= <客户端ip,客户端端口,服务器端ip(确定1个),服务器端口(最多65536个)>
所以 socket连接数量远远不止65536个
然后就可以根据上面的大概计算结果去评估需要配置多高的服务器,找好合适的方案;
1.3. 性能测试
但是,如今的项目基本上都是前后端分离的,性能也分为前端性能和后端性能,通常默认是后端性能,即服务端性能,也就是对服务端接口做压测
1.3.1. 后端性能--服务端性能
如果是对一个接口(单场景)压测,且这个接口内部不会再去请求其它接口,那么tps=qps,否则,tps≠qps
如果是对多个接口(混合场景)压测,不加事务控制器,jmeter会统计每个接口的tps,而混合场景是要测试这个场景的tps,显然这样得不到混合场景的tps,所以,要加了事物控制器,结果才是整个场景的tps。
每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下降。
1.4. 性能优化
1.4.1. 场景
1.4.1.1. IO密集型
IO密集型的(如大量访问igraph),
1.4.1.2. 计算密集型
有CPU密集型的,一个场景可能在cpu不超过30%的情况下,就已经出现了大量的异常QPS,Load很高,需要增加机器。
1.4.1.3. 网络密集型
| 应用 | 最低网速要求 |
|---|---|
| 文件聊天 | 5kbps |
| 网页浏览 | 20Kbps |
| 网络游戏 | 50Kbps |
| 在线音乐 | 128Kbps |
| 高清视频 | 4Mbps |
| 超清视频 | 6MKbps |
1.4.2. 集群
将多台服务器组成集群,使用负载均衡将请求转发到集群中,避免单一服务器的负载压力过大导致性能降低。
1.4.3. 缓存
缓存能够提高性能的原因如下:
- 缓存数据通常位于内存等介质中,这种介质对于读操作特别快;
- 缓存数据可以位于靠近用户的地理位置上;
- 可以将计算结果进行缓存,从而避免重复计算。
1.4.4. 异步
某些流程可以将操作转换为消息,将消息发送到消息队列之后立即返回,之后这个操作会被异步处理。
2. 伸缩性
指不断向集群中添加服务器来缓解不断上升的用户并发访问压力和不断增长的数据存储需求。
2.1. 伸缩性与性能
如果系统存在性能问题,那么单个用户的请求总是很慢的;
如果系统存在伸缩性问题,那么单个用户的请求可能会很快,但是在并发数很高的情况下系统会很慢。
2.2. 实现伸缩性
应用服务器只要不具有状态,那么就可以很容易地通过负载均衡器向集群中添加新的服务器。
关系型数据库的伸缩性通过 Sharding 来实现,将数据按一定的规则分布到不同的节点上,从而解决单台存储服务器的存储空间限制。
对于非关系型数据库,它们天生就是为海量数据而诞生,对伸缩性的支持特别好。
3. 扩展性
指的是添加新功能时对现有系统的其它应用无影响,这就要求不同应用具备低耦合的特点。
实现可扩展主要有两种方式:
- 使用消息队列进行解耦,应用之间通过消息传递进行通信;
- 使用分布式服务将业务和可复用的服务分离开来,业务使用分布式服务框架调用可复用的服务。新增的产品可以通过调用可复用的服务来实现业务逻辑,对其它产品没有影响。
4. 可用性
4.1. 冗余
乐视网 服务器20%冗余量1
保证高可用的主要手段是使用冗余,当某个服务器故障时就请求其它服务器。
应用服务器的冗余比较容易实现,只要保证应用服务器不具有状态,那么某个应用服务器故障时,负载均衡器将该应用服务器原先的用户请求转发到另一个应用服务器上,不会对用户有任何影响。
存储服务器的冗余需要使用主从复制来实现,当主服务器故障时,需要提升从服务器为主服务器,这个过程称为切换。
4.2. 监控
对 CPU、内存、磁盘、网络等系统负载信息进行监控,当某个信息达到一定阈值时通知运维人员,从而在系统发生故障之前及时发现问题。
是描述服务器或操作系统性能的一些数据指标,如使用内存数、进程时间,在性能测试中发挥着“监控和分析”的作用,尤其是在分析统统可扩展性、进行新能瓶颈定位时有着非常关键的作用。
资源利用率:指系统各种资源的使用情况,如cpu占用率为68%,内存占用率为55%,一般使用“资源实际使用/总的资源可用量”形成资源利用率。
4.2.1. 系统资源消耗指标
4.2.1.1. CPU
cat /proc/cpuinfo >>> processor :系统中逻辑处理核的编号 vendor_id :CPU制造商 cpu family :CPU产品系列代号 model :CPU属于其系列中的哪一代的代号 model name:CPU属于的名字及其编号、标称主频 stepping :CPU属于制作更新版本 cpu MHz :CPU的实际使用主频 cache size :CPU二级缓存大小 physical id :单个CPU的标号 siblings :单个CPU逻辑物理核数 core id :当前物理核在其所处CPU中的编号,这个编号不一定连续 cpu cores :该逻辑核所处CPU的物理核数 apicid :用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续 fpu :是否具有浮点运算单元(Floating Point Unit) fpu_exception :是否支持浮点计算异常 cpuid level :执行cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容 wp :表明当前CPU是否在内核态支持对用户空间的写保护(Write Protection) flags :当前CPU支持的功能 bogomips :在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second) clflush size :每次刷新缓存的大小单位 cache_alignment :缓存地址对齐单位 address sizes :可访问地址空间位数 power management :对能源管理的支持
4.2.1.2. 系统负载 Load
Linux的Load(系统负载),是一个让新手不太容易了解的概念。load的就是一定时间内计算机有多少个active_tasks,也就是说是计算机的任务执行队列的长度,cpu计算的队列。
top/uptime 等工具默认会显示1分钟、5分钟、15分钟的平均Load。
$ w load average: 0.52, 0.58, 0.59 1分钟平均负载,5分钟平均负载,15分钟平均负载分别 0.52, 0.58, 0.59
系统负载分析
-
数值含义
具体来说,平均Load是指,在特定的一段时间内统计的正在CPU中运行的(R状态)、正在等待CPU运行的、处于不可中断睡眠的(D状态)的任务数量的平均值。
Load<1:没有等待
Load==1:系统已无额外的资源跑更多的进程了
Load>1:进程都堵着等待资源 -
不同时间的数值含义
1)1分钟Load>5,5分钟Load<1,15分钟Load<1
短期内繁忙,中长期空闲,初步判断是一个抖动或者是拥塞前兆
2)1分钟Load>5,5分钟Load>1,15分钟Load<1
短期内繁忙,中期内紧张,很可能是一个拥塞的开始
3)1分钟Load>5,5分钟Load>5,15分钟Load>5
短中长期都繁忙,系统正在拥塞
4)1分钟Load<1,5分钟Load>1,15分钟Load>5
短期内空闲,中长期繁忙,不用紧张,系统拥塞正在好转 -
数值与场景
CPU密集型的程序在运行那么CPU利用率高,Load一般也会比较高。
I/O密集型的程序在运行,可能看到CPU的%user, %system都不高,%iowait可能会有点高,这时的Load通常比较高。
4.2.2. 系统用户规模指标
4.2.2.1. PV 页面累计浏览量
PV 即 page view,页面浏览量 用户每一次对网站中的每个页面访问均被记录1次。用户对同一页面的多次刷新,访问量累计。
4.2.2.2. UV 同一客户端访问量(独立访客量)
UV 即 Unique visitor,独立访客 通过客户端的cookies实现。即同一页面,客户端多次点击只计算一次,访问量不累计。
4.2.2.3. IP 同一ip的访问量
IP 即 Internet Protocol,本意本是指网络协议,在数据统计这块指通过ip的访问量。 即同一页面,客户端使用同一个IP访问多次只计算一次,访问量不累计。
4.2.2.4. DAU 日活用户数
日活用户数,简称日活,DAU(Daily Active User)
4.2.2.5. MAU 月活用户数
月活用户数, MAU(Monthly Active Users)
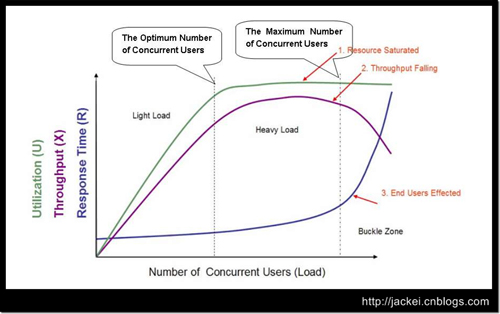
4.3. 服务降级
服务降级是系统为了应对大量的请求,主动关闭部分功能,从而保证核心功能可用。
5. 安全性
要求系统在应对各种攻击手段时能够有可靠的应对措施。
6. 性能瓶颈分析
瓶颈分析是应用运维老生常谈的一个事儿,经常做,今天总结一下,希望对你有所帮助。
不管什么业务,吞吐量的本质是木桶原理,能跑多大量取决于木桶最短那个板(脑袋里是不立刻出现了木桶模型,哈哈)!!换句话说,当有能力提高短板的高度时,业务的吞吐量就会上升,但同样有个边际效应,经过多次的优化后,当再次提高短板的成本非常非常大,而提高的量却很低时,那就不要较劲了,直接加服务器吧。
言归正传,先讲一下QPS跑不上去的现象,表现就是高过一个点后错误率增加、响应时间变长、用户体验变差,带来的副作用就是用户的流失,很显然是遇到瓶颈了,那么瓶颈在哪儿,我们怎么分析呢?
开发二话不说要求加服务器,作为应用运维不过脑子直接向老板要么?服务器或许已经够多了,用户总量你心中知道没有多少,用户增量也没多少,但业务上对服务器的需求却像无底洞一样,需要不停的扩容再扩容,其实这个时候就该静下心来分析一下了,到底是什么原因导致吞吐量跑不上去?负责任的说,运维给公司省钱就是给公司挣钱了,抓到点上这个数字还特别的可观,总结后,一般瓶颈问题从下面三个维度来分析。
一、机器本身
分析的整体方法是由浅入深、层层深入,先看服务器本身的指标有没有遇到短板,这个层面的分析也是相对最容易的,在配置层面(ulimit相关例如fd等)检查没有问题后,从下面四个方面进行分析。
1、cpu
cpu粗面上看有两个指标,当前使用率和负载,使用率反应的是当前cpu使用的情况,而负载反应的是cpu任务的队列情况,也就是说任务排队情况。一般cpu使用率在70%以下,负载在0.7*核心数以下,cpu的指标就算正常。
也有例外情况得分析cpu的详细指标,在运维小米消息系统的一个模块时,服务器用的是阿里云的ecs,整体cpu利用率不到30%,但业务就是跑不上量,和肖坤同学查后发现cpu0的软中断极高,单核经常打到100%,继续查后发现网络中断都在cpu0上无法自动负载,和阿里云工程师确认后是所在机型不支持网卡多队列造成的,最终定位cpu的单核瓶颈造成了业务整体瓶颈,如下图:
image.png
cpu用满的解决办法简单粗暴,在程序无bug的前提下,换机型加机器,cpu本身没单独加过。
附一篇排查cpu问题的博文:4核服务器cpu使用率10%负载飙到23.5故障排查
2、内存
内存常规看的是使用率。这个在做cdn的小文件缓存时遇到过,当时用的是ats,发现程序经常重启,业务跟着抖动,查日志后发现系统OOM了,当内存快要被占满的时候,kernel直接把ats的进程给杀掉,然后报out of socket memory,留的截图如下:
1491836023709950.png
同样,在应用层没有优化空间时,那就加内存吧!!
3、IO
IO主要指硬盘,一般用iostat -kdx 1看各种指标,当 %util超过50%,且偶发到100%,这说明磁盘肯定是到瓶颈了。
要进一步查看是否由于IO问题造成了系统堵塞可以用vmstat 1 查看,下图b对应因IO而block的进程数量。
image.png
这个在新浪做图片业务时遇到过,是一个源站的裁图业务,设计上为了避免重复裁图,在本地硬盘上存了一份近7天的数据,由于用python写的,没有像JVM那种内存管理机制,所有的IO都在硬盘上。有一天业务突然挂了,和开发查了2个多小时未果,中间调整了各种参数,紧急扩容了两台机器依然不起作用,服务的IO高我们是知道的,查看IO数据和历史差不多,就没往那方面深考虑,后邀请经验颇多的徐焱同学参与排查,当机立断使用挂载内存的方式替换掉硬盘的IO操作,IO立马下来了,服务恢复。
IO问题也得综合的解决,一般从程序逻辑到服务器都要改造,程序上把重IO的逻辑放在内存,服务器上加SSD吧。
4、网络
网络主要是看出、入口流量,要做好监控,当网卡流量跑平了,那么业务就出问题了。
同样在运维图片业务时遇到过网卡跑满的情况,是一个图片(小文件)的源站业务,突然就开始各种5XX告警,查后5XX并无规律,继而查网卡发现出口流量跑满了,继续分析,虽然网卡是千兆的,但按理就cdn的几个二级回源点回源,不至于跑满,将文件大小拿出来分析后,发现开发的同学为了省事儿,将带有随机数几十M的apk升级包放这里了,真是坑!!
网卡的解决方式很多,做bond和换万兆网卡(交换机要支持),当前的情况我们后来改了业务逻辑,大于多少M时强制走大文件服务。
二、程序代码
当查了cpu、内存、IO、网络都没什么问题,就可以和开发好好掰扯掰扯了,为什么服务器本身没什么压力,量却跑不上去,不要以为开发写的程序都很优良,人无完人何况是人写出来的程序呢?很多时候就是程序或技术架构本身的问题跑不上去量,这个过程运维还是要协助开发分析代码逻辑的,是不是程序cpu和内存使用的不合理,是不是可以跑一下多实例,把某些逻辑比较重的地方做下埋点日志,把执行的全过程apm数据跑出来进行分析,等等。
一个典型用运维手段解决代码瓶颈的案例详见博文:记一次HttpDns业务调优——fastcgi-cache性能提升5倍
三、逻辑架构
发展至今,微服务架构设计已成为大型互联网应用的标配,各模块间通过HTTP、RPC等相互依赖调用,如果查完服务器、程序依然没有问题,再往深处走就得协同开发分析逻辑架构了,这也是微服务系统下的一个特色,不是因为服务器或者程序bug造成了业务瓶颈,而是某个模块的短板造成了整个业务吞吐量上不去,这个很好理解,甚至有很多接口用的是公网公共服务。
具体分析上,从一次完整请求的角度,从头到尾理一遍外部依赖的上下游资源和调用关系,外部资源包括api接口、DB、队列等,然后在每个点做埋点日志,将数据进行分析,我们在线上用这种方法不知道分析出了多少瓶颈,如果程序没有做很好的降级熔断,由于程序本身的执行是堵塞的,一个接口慢影响到整个请求,进而QPS上来后请求变慢错误数增高的例子很多,在这种情况下,如果瓶颈的接口是别的部门或公网资源,加多少服务器都解决不了问题,进行改造吧,下图是运维门户业务时做的依赖接口超时监控,性能差的接口一目了然:
03后端依赖接口.png
好了,写到这,希望对遇到问题不知如何下手的你有所帮助!!
7. 最大进程数量
cat /proc/sys/kernel/threads-max
查系统支持的最大线程数,一般会很大,相当于理论值
该命令在不同的机器上 值不一样。
在centos 服务器上面 : 513845
在ubuntu16.04 pc机上面 : 62667
cat /proc/sys/kernel/pid_max 在centos 服务器上面 :32768 在ubuntu16.04 pc机上面 : 32768 系统限制某用户下最多可以运行多少进程或线程 -u 进程数目:用户最多可启动的进程数目.
